Coding Period Week 3

Week 3 Progress (June 10 - June 16)
This week mostly went through passing the tests in the Draft PR and written a basic test for the Post Scan Plugin --package-summary with pytest in commit.
Implemented a unit test for the basic plugin:-
Imported required modules in
test_package_summary1 2 3 4 5 6 7 8
import pytest from os import path from commoncode.testcase import FileDrivenTesting from scancode.cli_test_utils import check_json_scan from scancode.cli_test_utils import run_scan_click from scancode_config import REGEN_TEST_FIXTURES from summarycode.package_summary import PackageSummary
Added the basic test
test_package_summary_plugin1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
class TestPackageSummary(FileDrivenTesting): test_data_dir = path.join(path.dirname(__file__), 'data') def test_package_summary_plugin(self): test_dir = self.get_test_loc('package_summary/basic-plugin-testing/codebase/') result_file = self.get_temp_file('json') expected_file = self.get_test_loc('package_summary/basic-plugin-testing/expected.json') # Run the scan with the package summary option run_scan_click([ '--package-summary', '--json-pp', result_file, test_dir ]) check_json_scan(expected_file, result_file, remove_uuid=True, remove_file_date=True, regen=REGEN_TEST_FIXTURES)
The test uses data located in tests/ with the following directory structure:
1 2 3 4 5 6 7
. ├── codebase │ ├── README.txt │ ├── mit.LICENSE │ ├── src │ └── tests └── expected.jsonThis directory contains dummy data for the test, with expected.json as the result.
After that tested this test with
pytest tests/summarycode/test_package_summary.py
Discussions
Had discussions with mentors about the PR as it was failing many tests. 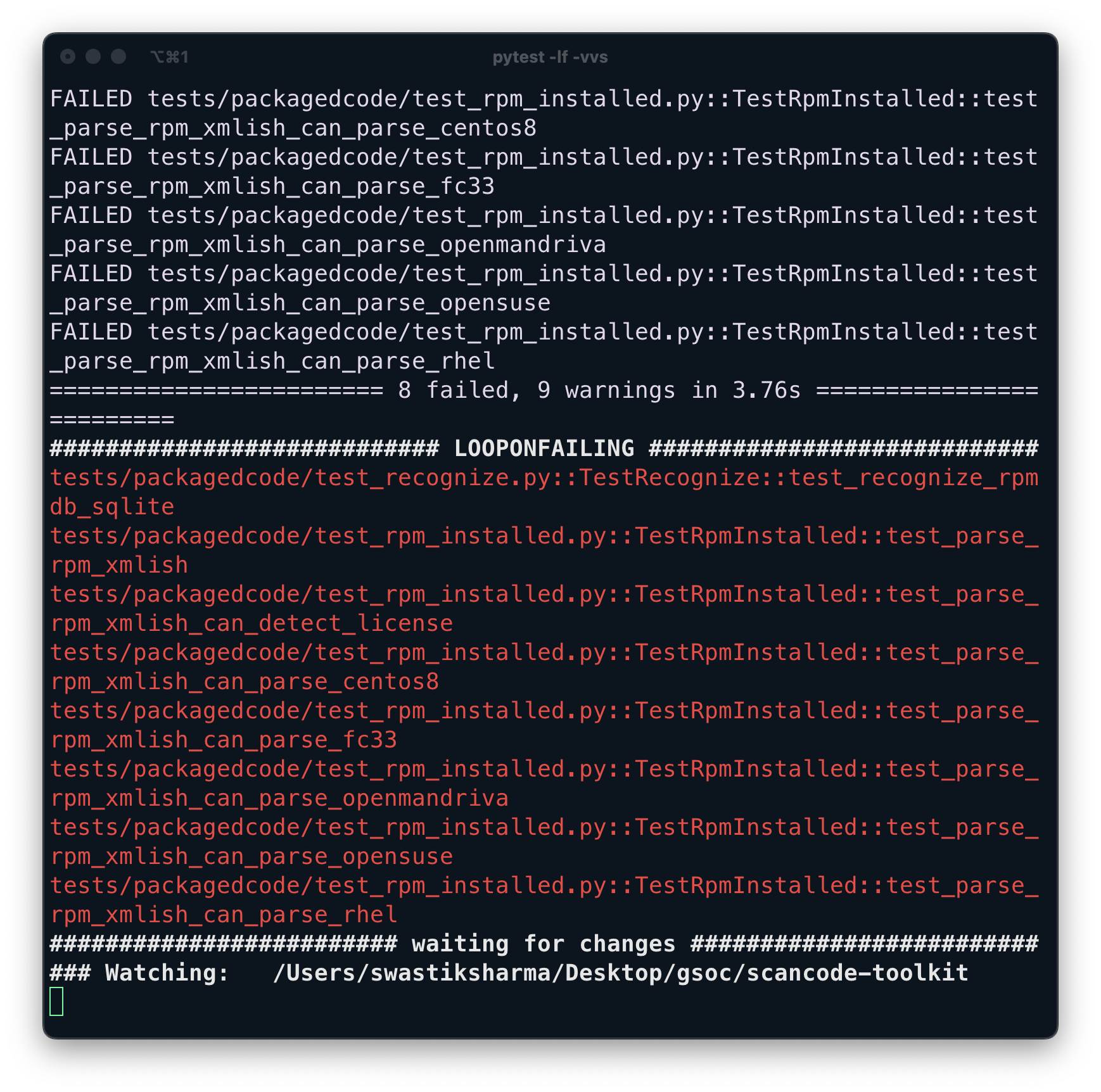
About 109 tests were failing, so they suggested regenerating the test results because of changes in the Package model affecting many tests. To regenerate the test results, I used the command:
1
SCANCODE_REGEN_TEST_FIXTURES=yes pytest -vvs tests/packagedcode/test_recognize.py
This command modified all unit tests in test_recognize.py, resulting in about 380+ file changes. It became clear that regenerating only specific failing tests was necessary, using:
1
SCANCODE_REGEN_TEST_FIXTURES=yes pytest -vvs tests/packagedcode/test_recognizepy::TestRecognize::test_recognize_rpmdb_sqlite
By looping over the failed tests using:
1
pytest -lf -vvs
I was able to regenerate specific tests. The -lf flag ensures it loops over the failed tests.
After regenerating all the failed tests, there were only minor changes in about 100 files, all necessary due to the model change for License_clarity in the top-level package model.
Conclusion and Further Plans
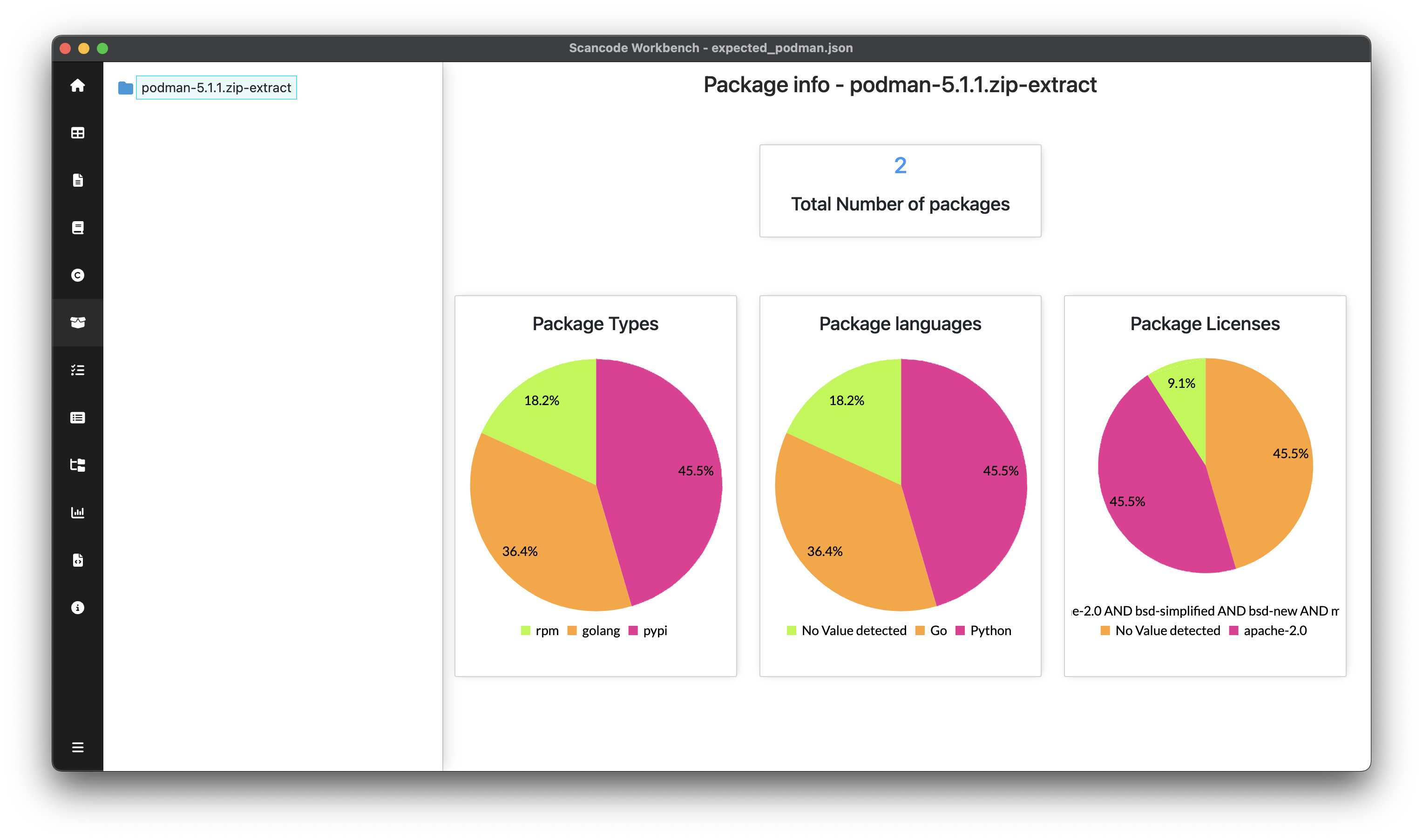
With all tests passing, the next step is to implement the code for populating the License Clarity field with sufficient and well-calculated data. Mentors suggested analyzing scan results from codebases with more than one top-level package, using examples such as:
- https://github.com/containers/podman
- https://github.com/graphile/crystal
- https://github.com/tokylabs/Windows-web-bluetooth
For analyzing the scan results, it was suggested to use the ScanCode Workbench that provides an advanced visual UI to help quickly evaluate licenses and other notices.
Attendees
Visitor Count
